情報ネットワーク・メディア研究室
個人情報保護、デジタル著作権管理、電子商取引、情報検索などに機械学習を応用してネットワークを安全・安心に利用できるシステムを研究しています。
非文字資料研究センター共同研究 http://himoji.kanagawa-u.ac.jp
非文字資料の流通過程における諸問題を解決するための機械学習やブロックチェーンなどを応用した基盤技術に関する研究
非文字資料研究において研究者と一般の資料提供者が協力して資料の収集整理を行い、その研究成果を社会に発信し還元するためには、「資料の関連性や作業内容に即した検索とマイニング」、資料提供者や研究者の個人情報や重要情報、著作権の管理、資料提供や作業の対価やインセンティブとなる「多様な価値観に基づく地域通貨的価値交換」が必要となる。本研究では、「知識とサービス、物の流通と価値交換」、「知識とサービスの検索とマイニング」、「個人情報や重要情報、著作権の管理」で必要な基盤技術に機械学習とブロックチェーンなどを応用する。具体的にはアクセス制御で必要な資料間の関係性や電子透かしで必要な画像固有の情報の抽出に機械学習を利用したり、流通過程のコンテンツの作成、登録、利用、譲渡、二次利用などの時系列をともなう事象の発生をブロックチェーンを利用して信頼できる第三者を仮定することなく行うことなどが挙げられる。また、福島県只見町で収集されている民具のデータベース化と研究者と利用者が使いやすい検索システムの構築に取り組んでいる。
只見町インターネットエコミュージアムhttp://www.himoji.jp/himoji/tadami-item/index.html

福島県只見町での現地調査 
福島県只見町収蔵の民具
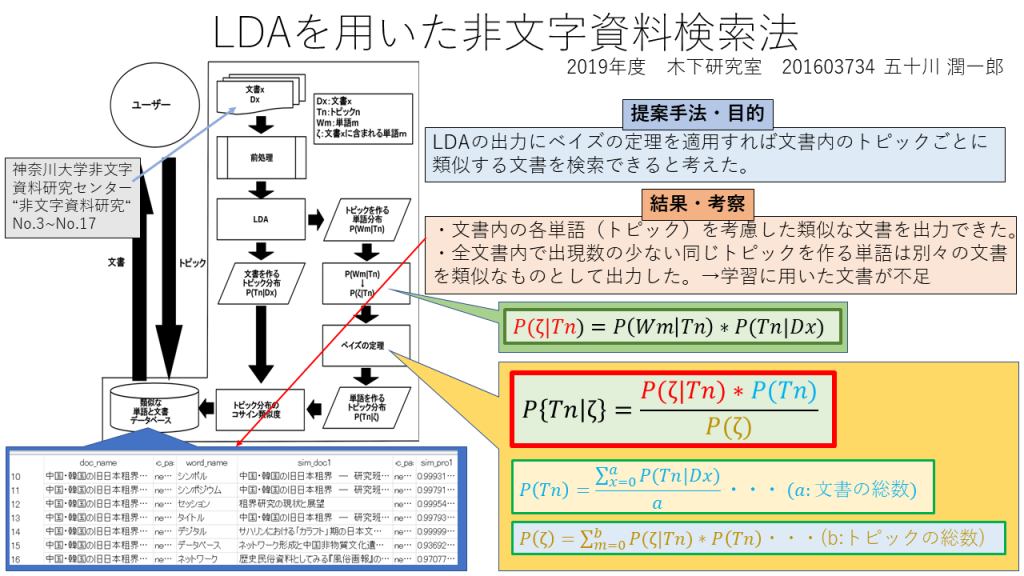
LDAを用いた非文字資料検索法
近年, インターネット上に日々大量の情報が増えてる. 紙の文書も電子データに変換する試みも増え,書籍を調べるよりもインターネットを利用して調べるほうが素早く多くの情報を比較できる. 正確で早い検索を可能にする,文書の意味をメタデータに記述する方法や,文書中の単語を意味解析し自動で分類する方法が研究されている.トピックモデルは文書が複数の潜在的なトピックから確率的に生成しているという考え方で,pLSA やLDAという手法を用いることでコンピュータで文書のトピックモデルを計算することができ,文書のトピック分布を比較することにより文書間の類似度を測れる.そこでLDA の出力にベイズの定理を用いることにより算出される” 単語を構成するトピック分布” を用いて単語と文書の類似度を測れるのではないかと予想した.本研究では,LDA の出力にベイズの定理を用いることにより算出される” 単語を構成するトピック分布” と文書を構成するトピック分布の類似度から,文書中の特定の単語に注目した時に現れる類似な文書を提示するシステムのモデルを提案した.
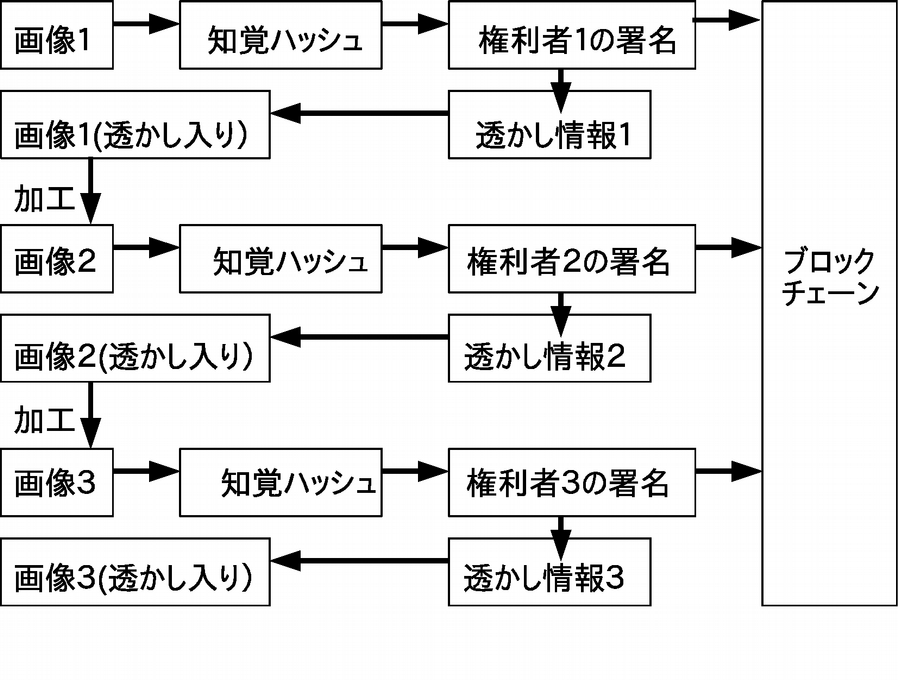
電子透かしとブロックチェーンを用いたデジタル著作権保護
信頼できる第三者が不要な多重電子透かし二次著作物など複数の権利者が介在している場合、創作や加工の順序を明示する必要がある。従来は信頼できる第三者が情報を管理していたが、コストやプライバシー保護、セキュリティの観点から望ましくない。一方、ブロックチェーン技術に基づいた仮想通貨やスマートコントラクトが普及してきており、著作権管理の分野にも利用され始めている。ブロックチェーンは信頼できる第三者に依存することなく、権利の移転などのイベント発生の時系列の保証を行うことができる。コンテンツの情報そのものをブロックチェーンに記録することは容量的に現実的ではないため、代わりにハッシュ値を記録しコンテンツ自体は別のストレージに蓄積することになる。しかし、SHA256 などの暗号学的一方向性ハッシュ関数を冗長性の高い画像情報などに適用すると、加工および符号化により視覚的には差異を検出できなくても異なるハッシュ値となってしまう。そこでコンテンツの加工に耐性のある知覚ハッシュが必要となる。図のように対象となる原画像から得られる知覚ハッシュと知覚ハッシュに権利者が署名したものを電子透かしとして埋め込むとともにブロックチェーンに記録する。これにより、透かし情報の他のコンテンツへの流用を防止できる。署名には権利者に関する情報などのコンテンツのメタデータも含まれる。二次利用の権利者は同様の手順で透かし情報を埋め込みブロックチェーンに記録する。ブロックチェーンにより複数の権利者が電子透かしを埋め込む多重電子透かしの埋め込み順序などが保証できる。
個人情報保護や情報漏洩を防止するための推論攻撃の解析
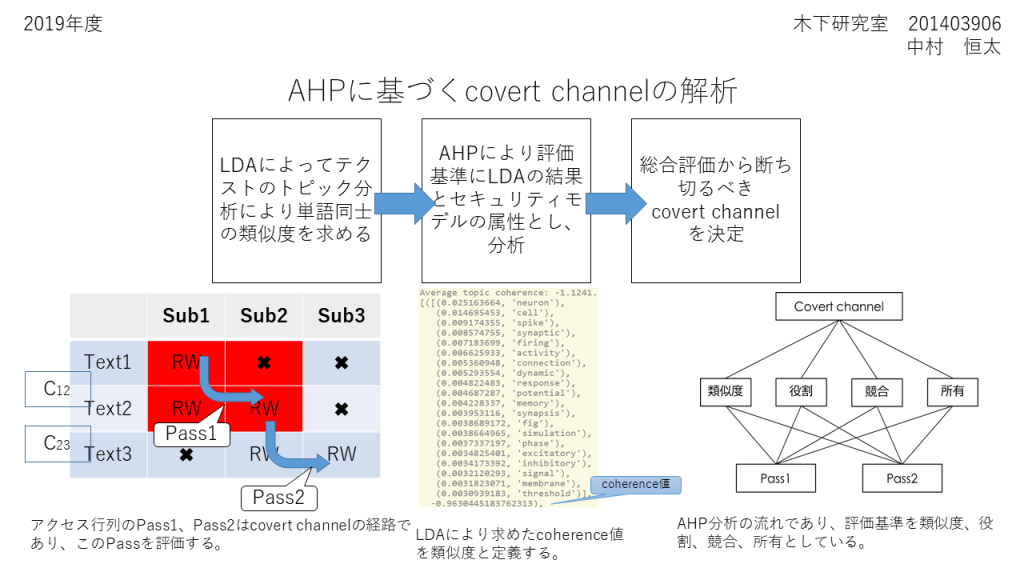
ストレージからの情報漏洩を防ぐために、アクセス制御が使われている。アクセス行列は一般にcovert channel と呼ばれる情報漏洩を引き起こす経路が存在する。従来このcovert channel の評価はセキュリティモデルによって行われてきた。しかし、人と人の関係、あるいは人と情報の関係を論理学的モデルによって示すことは、それによって表現される応用的現場を限定させることになり、使い勝手が悪くなるという問題があった。本研究は神奈川大学非文字資料研究センターで行われている「非文字資料」をデータベース化するという研究に関連している。この非文字データベースにおいても、covert channel が起こり、情報漏洩につながる可能性がある。そこで、大量のテクストをトピック分析し、テクストの確率変数としてのクラスタを学習させ、クラスタの中にあるテクスト同士の類似度を確率的に求める。次に人と人の関係、人と情報の関係をセキュリティモデルの属性から役割、競合、および所有と定義する。最後に、テクストの類似度、役割、競合、所有を階層分析法(AHP)の評価基準と定義し、意思決定を支援するAHP 分析によって複数のcovert channel を評価し、切断するべきcovert channel を選択する、というモデルを提案した。
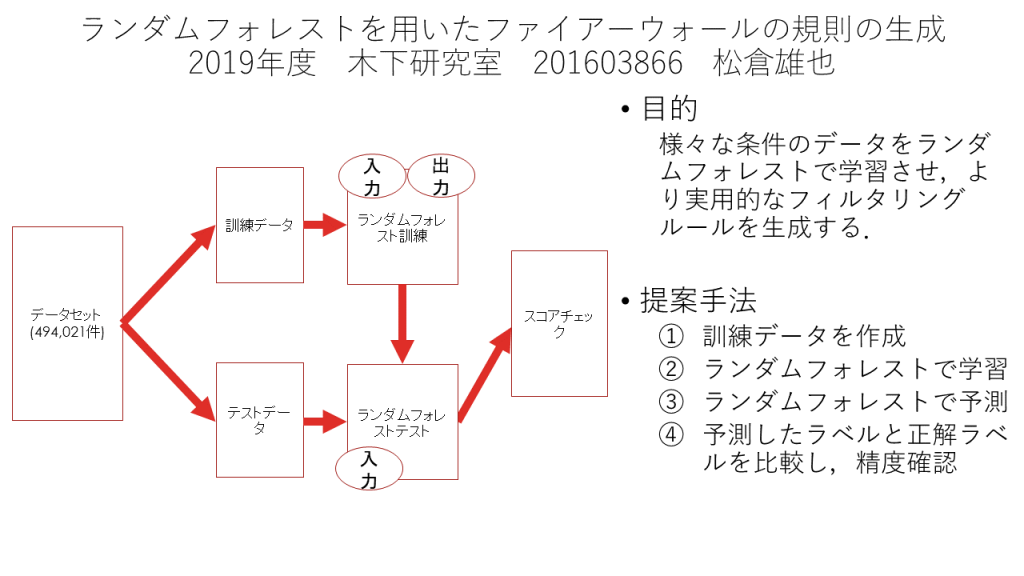
ネットワークの不正侵入を防ぐファイアウォールと侵入検知
近年,ネットワークの発達によって技術の向上がみられる反面,これを悪用したサイバー犯罪が問題となっている.そのサイバー犯罪を防衛するシステムに「ファイアーウォール」がある.ファイアーウォールのルールはセキュリティポリシーに沿って,手動で設定する,しかし手動設定では設定をし忘れるとルールは正しく作成されず,その部分をついて攻撃される危険がある.こうした問題に,教師あり学習のランダムフォレストを用いることで,セキュリティポリシーに沿ったルールを自動でACL (アクセスコントロールリスト) に適用するシステムを提案した.さらに様々な条件のデータをランダムフォレストによって学習させ,より実用的なルールを作成するシステムを提案した.